AUTHORS

Marco Pesarini
Partner @Bip xTech

Giuseppe D’Agostino
Senior Cloud & Data
Architect @Bip xTech

Luca Natali
Senior Cloud & Data
Architect @Bip xTech

Martino Ongaro
Cloud & Data Engineer
@Bip xTech
The data lake has always been one of the founding pillars at the base of data-driven organizations, a business philosophy towards which all modern companies have been striving this past decade. In essence, a data lake is a large IT archive where all corporate data can be transferred, as they are, without transformations, to make the data accessible to all functions; in other words, a democratization of access to data.
In this design, the data is given an intrinsic, almost natural value. Leveraging new technologies, ranging from data engineering to data science, anyone can access the data and draw evidence, a meaning, without the need to have too much experience of the context from which the data derives.
Working over the years in many related projects, however, we have found that the model suffers from some underlying complications. This drive to extract the raw data from the domain of its birth and process it in centralized platforms, has created two problems which will be familiar to anyone who has practiced in this field: the inherent difficulty in searching for and interpreting the data for those ignorant of the data’s origin, and the chronic low quality of the data stemming from the fact that whoever extracts the data from its birth domain is not then made responsible for its use.
To address these problems, companies are increasingly equipping themselves with complex data governance structures, which define responsibilities, processes and roles to ensure data clarity and preserve its quality. However, the solution to these problems cannot only be organizational. Companies also need technical help to simplify the substance of the model.
In this regard, Zhamak Dehghani’s intuition, professed in his article “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh”[1] is very interesting. In it, she proposes a new way of managing company data by providing for the analysis of the data in the domain of origin itself, the domain where the data is born. According to this approach, it is the experts of the origin domain themselves who are held responsible for said data interpretation and quality. Responsibility for customer data falls within the CRM domain, responsibility for budget data in the management system, the one for sales data in the e-commerce domain, and so on. It is easy to understand how in this design the problems related to interpretation and quality of the data substantially decrease, given the experience that abounds in the domain of the data’s origin.
The principal aspect of the intuition concerning the data mesh, however, lies in the solution proposed to avoid a relapse into the old world of information silos, in which the data was masked and lost in the various domains of origin. In data mesh domains are given the responsibility for creating data products which are software tools for visualizing and interpreting data to be published throughout the company. These products are made available in the company internal information market and can be remunerated, i.e. provided with a budget for their growth, depending on how much they are actually used or subscribed to by other users.
A free market is created – and this is the challenge of the tools supporting the data mesh – in which all users can find and consume all the corporate data products, and from the natural competition for the budget among the domains derives a beneficial boost to disclose and share data.
The data thus reported under the responsibility of the domain, but in a market where individual domains are motivated to expose said data and make them understandable and of quality. This puts domain experience at the basis of data valorisation.
How a data mesh is composed
The data mesh bases its theoretical foundations on the architectural model of Domain-Driven Design (DDD), according to which software development must be closely linked to the business domains within an organization. In the DDD, each organizational domain can be represented by a domain model, that is a combination of data, characteristic behaviors and business logic that guide the development of the domain software. The main purpose of the DDD is to create pragmatic, consistent and scalable software, breaking down the architecture into services within individual domains and focusing on their reusability in the composition of the different software products supporting the company. The first implementation of DDD in enterprise software was the revision of monolithic applications towards microservice-based architectures: each microservice is circumscribed in a domain and is responsible for satisfying the requirements of a specific functionality by providing an application function to all the products that request it.
The data mesh applies the DDD to the architectures in the data domain. Data products, as they name them, allow access to domain data through elementary functions that expose precise interfaces and make raw data, pre-processed or processed data available. Just as microservices are software components that expose elementary application functionalities, data products are software components that expose elementary data and analytic functionalities within the domain. Data products have the objective of dividing the analytical functions of the domain into elementary and reusable products, such as microservices subdivide the application functions.
As with microservices, also in the data mesh, the new disaggregated model needs a series of rules and tools to maintain good governance of the whole.
First of all, the data products must respect some characteristics, which are functional to create the free market we were talking about. Regardless of how the specific data access interface is created – it is possible to give access through an API, through a view on a database, or through a virtualization system – or the type of data that is made available, the data products must respect the rules identified in the DATSIS acronym according to which a data product must be:
- Discoverable – consumers must be rendered autonomous in researching and identifying the data products created by the different domains
- Addressable – data products must be identified with a unique name following a common nomenclature
- Trustworthy – data products are built by the domains that hold the data and they must make quality data available
- Self-describing – consumers need to be able to use data without having to ask domain experts what it means
- Integrated – must be created following shared standards to be easily reused to create other data products
- Secure – data product must be secure by design and the access to data must be centrally regulated through access policies and security standards
Only by respecting these rules it is possible to create data products that allow an effective and reliable mesh design.
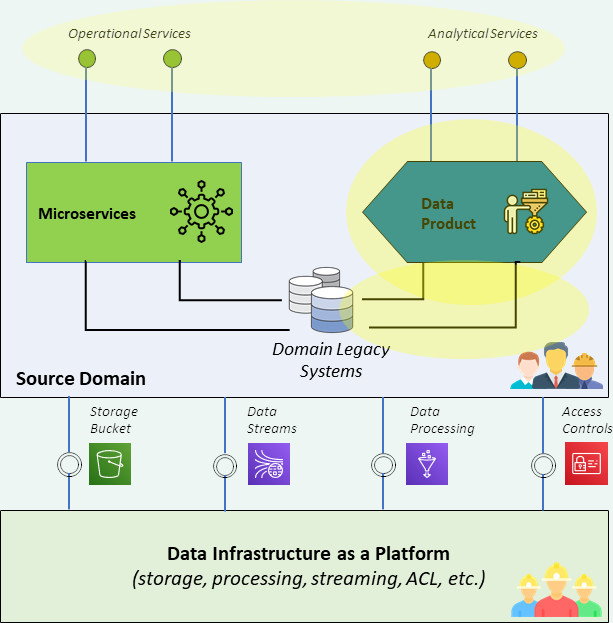
Moving on to the tools, there are two essential factors for building a functioning data mesh: data infrastructure as a platform and ecosystem governance.
By enforcing the requirement that individual application domains develop their data products, the organization risks seeing an increase in the heterogeneity rate of the technologies in use, hence making the sourcing strategy very complex. In the implementation of a data mesh, it is therefore important for an organization to equip itself with a common infrastructural platform – the data infrastructure as a platform – which supplies the basic building blocks for the creation and use of data products to all domains: storage, pipeline, database, calculation functions, just to name a few. Any domain that wants to set up its own data products will have to make use of these bricks by accessing the data infrastructure as a platform in self-serve mode. This allows the standardization of data products development and the introduction of a common language among the various domains. PaaS cloud platforms are an interesting option to build this common infrastructure on which to build data products; an option that could offer cost-controlled adoption and speed of implementation.
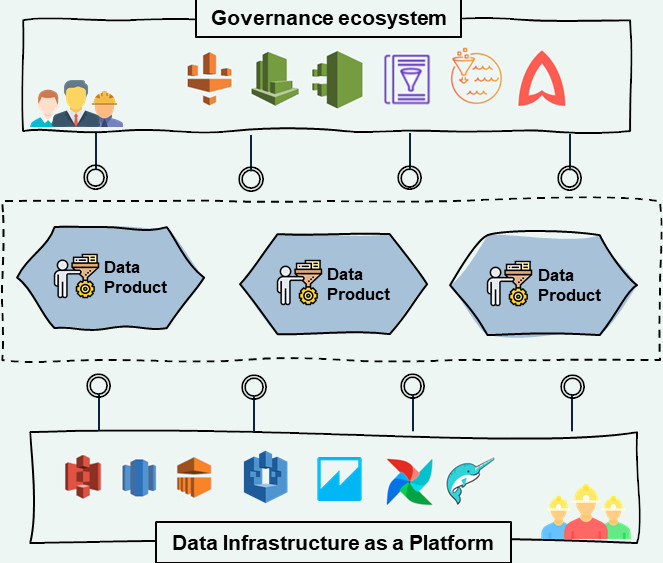
The creation of data products in distributed mode risks also to increase the duplication rate and the complexity of the access to the data, losing the objectives of quality and responsibility pertaining to the data mesh paradigm. For this it is very important that the organization equips itself with ecosystem governance tools that help provide visibility and comprehensibility to data products, tools where each data product can be registered and rendered consequently searchable and reusable according to specific authentication and authorization policies.
Technical perspective
Now that the concepts of data product, data infrastructure as a platform and ecosystem governance have been presented, let’s go into a more technical perspective to give tangibility to this introduction.
First of all, data products are nothing more than sets of technological components, often already known to companies for loading, storing, processing, and analyzing data. For example, let’s take a data product that is a tool for producing a report on domain data and examine the bricks that can make up the data product.
As mentioned, the building blocks of the data product come from the data infrastructure as a platform. Here we find established technologies including object storage and event queues, a batch and streaming processing layer, and data consumption tools for reporting, BI, ML and AI. They are tools already widely known and adopted.
Taking the example of the data product that produces a report, the building blocks could be a storage that holds the files from which to extract data, a Spark engine for extraction and processing, a database where to support the processed data, an interface for the analysis and a view for the report and an API to deliver the results.
For the realization of the data product, the data infrastructure as a platform also has the task of providing the tools to allow the orchestration of components and collaboration between users. In it we find orchestration technologies (such as Airflow, Dagster, DataFactory), which allow to coordinate the execution of processing and the most recent data modeling tools, to facilitate collaboration in the development phase between engineers and analysts (e.g. Dremio, and the Data Build Tool).
In the case of our data product, these tools allow the orderly execution of the commands and functions that generate the report and a more effective collaboration between the data engineer who uses Spark to manage the data on the storage, the modeler who structures the data model on the database, the analyst who uses it for the exploration and the developer who distributes the results in the form of an API.
At this point, the data product is ready to be consumed even outside the domain, and here the ecosystem governance tools suitable for managing the catalog and distribution of data products come into play. Among the main tools for cross-domain organization we find federated technologies, data product cataloguing technologies, and data discovery technologies (such as Amundsen, Metacat, Atlas), which make them visible and usable to end users. With the inclusion of these tools, users from other domains can search and access the data product, using the semantic search capabilities or scrolling through the company’s central data product catalog.
To complete the ecosystem governance platform, there are functions overseeing compliance, data quality, access control and monitoring. The new Data Stewart in the hypothesis of an ecosystem based on AWS will exploit the automatic alerts of AWS Comprehend to identify privacy violations, Glue DataBrew to control the quality of the output of the new data product, Lake Formation to control its internal and external permissions to the domain and CloudTrail to monitor access and use.
Organizational Perspective
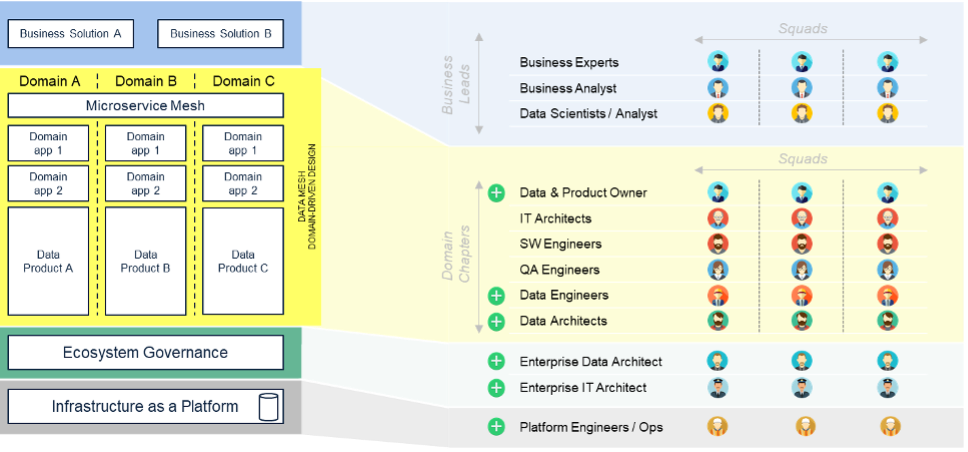
A final yet important aspect to consider in evaluating the data mesh paradigm is the organizational adaptation that its introduction may require. From this perspective, the transition is easier for those who have already adopted agile organizational models with competence domain chapters and project squads.
The principle of supplying data as a “product” sees the birth of new figures such as Data Product Owners – similar to the historical Product Owners – within the individual domains; figures responsible for the life cycle of data products (planning, monitoring, etc.) and for the execution of the domain data strategy.
Professional profiles already present in current organizations shall be distributed in the business domains: the decentralization of the ownership on the data, and of the processing of the same by the domain of competence, means that figures such as Data Engineers and Data Architects are distributed within the individual domains. The Data Engineers of the “customer” domain are to be identified, to give an example, as in the past the developers of vertical microservices were born within the same domain.
In such an organization that is distributed over domains, however, the function responsible for governance policies (interoperability, security, compliance, etc.) remains centralized. It is a central organizational entity that ensures the application of policies at the level of each domain. This entity is made up of technical figures at the enterprise level (for example, Enterprise Data Architects, Enterprise IT Architects, etc.), representatives of the domains and experts security and compliance.
The only other function that remains centralized in the model is that of overseeing the data infrastructure as a platform which manages the infrastructure for all domains with engineering and operation skills.
The data mesh is therefore a composition of many aspects, in a possible transformation of the data world towards a more agile and federated model.
Bip xTech, our Centre of Excellence on exponential technologies, employees experts in all the most advanced disciplines around data management; form data engineering to cloud, from data governance to microservice architectures; we can supply all the ingredients a the data mesh transition.
If you are interested in learning more about our offer or would like to have a conversation with one of our experts, please send an email to [email protected] with “Data Mesh” as subject, and you will be contacted promptly.
[1] https://martinfowler.com/articles/data-monolith-to-mesh.html
Read more insights